Semester Project
Projects
The following projects are given to CS graduate students.
Project 1: Erasure Code in Hadoop
- Implement an erasure code into Hadoop system
- Hadoop Version: 2.7 or higher
- Erasure Code: you can select one, but not RS (We recommend facebook LRC code)
- Test the storage efficiency of your proposed code
- Report and Source Code are required
- Source Code should be checked by TA
- References:
Project 2: Distributed Lock Design
- Design a simple consensus system, which satisfy the following requirements
- Contain one leader server and multiple follower server
- Each follower server has a replicated map, the map is consisted with the leader server
- The key of map is the name of distributed lock, and the value is the Client ID who owns the distributed lock
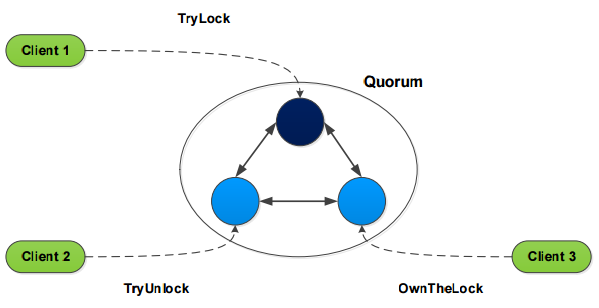
- Support multiple clients to preempt/release a distributed lock, and check the owner of a distributed lock
- For preempting a distributed lock
- -- If the lock doesn't exist, preempt success
- -- Otherwise, preempt fail
- For releasing a distributed lock
- -- If the client owns the lock, release success
- -- Otherwise, release fail
- For checking a distributed lock
- -- Any client can check the owner of a distributed lock
- To ensure the data consistency of the system, the follower servers send all preempt/release requests to the leader server
- To check the owner of a distributed lock, the follower server accesses its map directly and sends the results to the clients
- When the leader server handling preempt/release requests
- If needed, modify its map and sends a request propose to all follower servers
- When a follower server receives a request propose
- -- modify its local map
- -- check the request is pending or not
- -- if the request is pending, send an answer to the client
- In this system, all clients provide preempt/release/check distributed lock interface
- When a client is initialized
- Define the IP address of the target server
- Generate the Client ID information based on the user information(UUID)
- References
- Data structure of a client in the consensus system

Project 3: Distributed File System Design
- Design a Mini Distributed File System (Mini-DFS), which contains
- A client
- A name server
- Four data servers
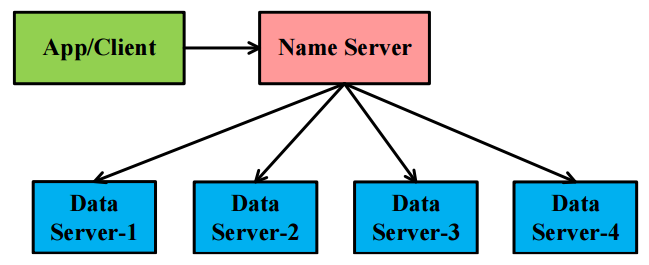
- Mini-DFS is running through a process. In this process, the name server and data servers are different threads
- Basic functions of Mini-DFS
- Read/write a file
- Upload a file: upload success and return the ID of the file
- Read the location of a file based on the file ID and the offset
- File striping
- Slicing a file into several chunks
- Each chunk is 2MB
- Uniform distribution of these chunks among four data servers
- Replication
- Each chunk has three replications
- Replicas are distributed in different data servers
- Name Server
- List the relationships between file and chunks
- List the relationships between replicas and data servers
- Data server management
- Data Server
- Read/Write a local chunk
- Write a chunk via a local directory path
- Client
- Provide read/write interfaces of a file
- Mini-DFS can show
- Read a file (more than 7MB)
- Via input the file and directory
- Write a file (more than 3MB)
- Each data server should contain appropriate number of chunks
- Using MD5 checksum for a chunk in different data servers, the results should be the same
- Check a file in (or not in) Mini-DFS via inputting a given directory
- By inputting a file and a random offset, output the content
- Bonus points
- Add directory management
- Write a file in a given directory
- Access a file via "directory + file name"
- Recovery
- Delete a data server (three data servers survive)
- Recover the data in the lost data server
- Redistribute the data and ensure each chunk has three replicas
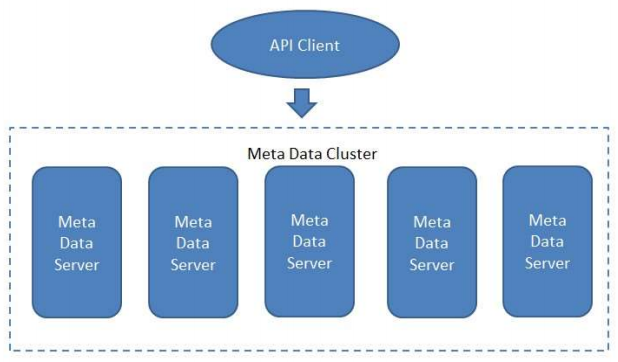
Project 4: Metadata Management in DFS
- Design a simple metadata management module for a distributed file system. Establish a distributed metadata cluster and a POSIX API based client
- The metadata management has the following functions
- Basic command set: support metadata operations via POSIX-based API
- i.e., mkdir, create file, readdir, rm file, stat, etc
- file handle can be ignored
- Distribution of metadata
- Metadata are distributed among various metadata servers
- Tests on the metadata management functions
- Input: Input the specified files & directories by client
- Output
- Traverse the files via readdir command
- List the status of a file via stat command
- Etc
- Write the metadata of these file operations into the metadata server
- Give the data distribution information of the whole cluster
- Consistent with other metadata servers
- Additional scores
- Support metadata server failover (process level)
- Support metadata server failure
- No metadata lost in the failure
- Implementation on the read/write operations of a file
Project Management
You should strongly consider using either
Subversion or
CVS
to perform source code control for your project and the paper
you write describing it. I suggest Subversion.
I also strongly suggest writing your course project report using
LaTeX.
It is the de-facto tool in which most CS research papers are written.
While it has a bit of start up cost, it's much easier to
collaboratively write complex research papers using LaTeX than using
word.
Writing Papers
Analysis
- Books: Raj Jain, the Art of Computer Systems Performance Analysis - a very good overview of lots of mathetmatical techniques and queueing bits, aimed at a systems audience