近期,中国计算机学会(CCF)推荐的A类国际学术会议SIGKDD2024论文接受结果公布,上海交通大学电子信息与电气工程学院计算机科学与工程系多项研究成果被收录其中。SIGKDD 被广泛认为是知识发现和数据挖掘研究最具影响力的学术会议,是数据挖掘领域中 h5 index 排名最高的学术会议/期刊,并被中国计算机学会(CCF)评为推荐CCF-A类会议。SIGKDD 2024 的录用率为20%。部分成果介绍如下:
论文1
论文题目:DAG:一种无需社群数目先验的属性图社群检测算法
作者及单位:
刘畅(上海交通大学),杨昱文(上海交通大学),卢宏涛(上海交通大学),吴梓明(腾讯),毕文东(腾讯),丁玥(上海交通大学),林文清(腾讯)
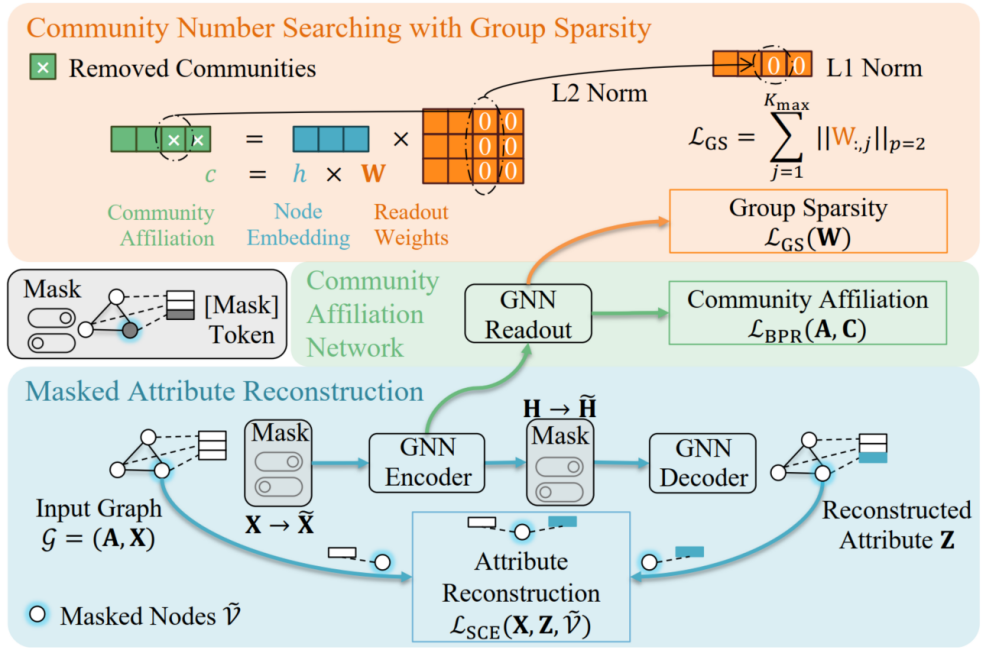
在腾讯互娱的工业场景中,社交网络具有规模大、语义丰富的特点,除了承载用户之间的关系链,社交网络也会反映用户的语义属性和对每种玩法的偏好程度等等。社群检测(community detection)将社交网络划分为一个个具有紧密连接和语义特性的子结构,可以更加了解用户偏好。目前,基于深度图聚类(DGC)的社群检测的方法无法自适应寻找社群数目,这使得其在真实场景中无法落地。
本研究首次针对属性图上无需先验的社群检测问题提出了一套针对性的图神经网络学习框架 DAG,它基于图神经网络的生成式自监督学习,以及基于社群隶属网络和组稀疏技术来进行自适应的社群数目搜索以及社群检测。该方法首次使得图神经网络模型克服了社群检测中社群数目未知的问题,并已部署于腾讯多款游戏中,相较于目前最先进算法提高了7.35%的新增好友数目。
论文2
论文题目:BBP:一种超越二元偏好的点击率预测模型训练框架
作者及单位:
刘畅(上海交通大学),汪琪炜(腾讯),卢宏涛(上海交通大学),丁玥(上海交通大学),林文清(腾讯)
点击率(CTR)预测任务在推荐系统中至关重要,旨在预测用户点击某个item的概率值。
研究团队将预测的概率值运用到各类推荐系统的下游任务中。在工业场景中点击率预测模型主要有两个场景:
- 排序:根据预测出的点击率生成一个排序的列表,为用户推荐点击概率更高的 item。
- 校准:使得预测出的点击概率和用户的真实点击率一致,这有助于更广泛的下游任务的建模,比如估算推荐的预期收益等。
在现实的推荐场景,比如在社交网络的好友推荐中,点击率预测的训练数据集由大量二元的点击标签组成,这使得在训练排序模型的过程中会出现大量的平局情况,制约排序模型的性能。此外,点击的标签占比总是十分稀疏,这导致在实际的训练中,浪费了绝大部分理论上可比较的样本。如果只有10%的样本是正样本,那么将有80%以上的比较情况将被浪费,而现实中这个比例只会比10%更小。
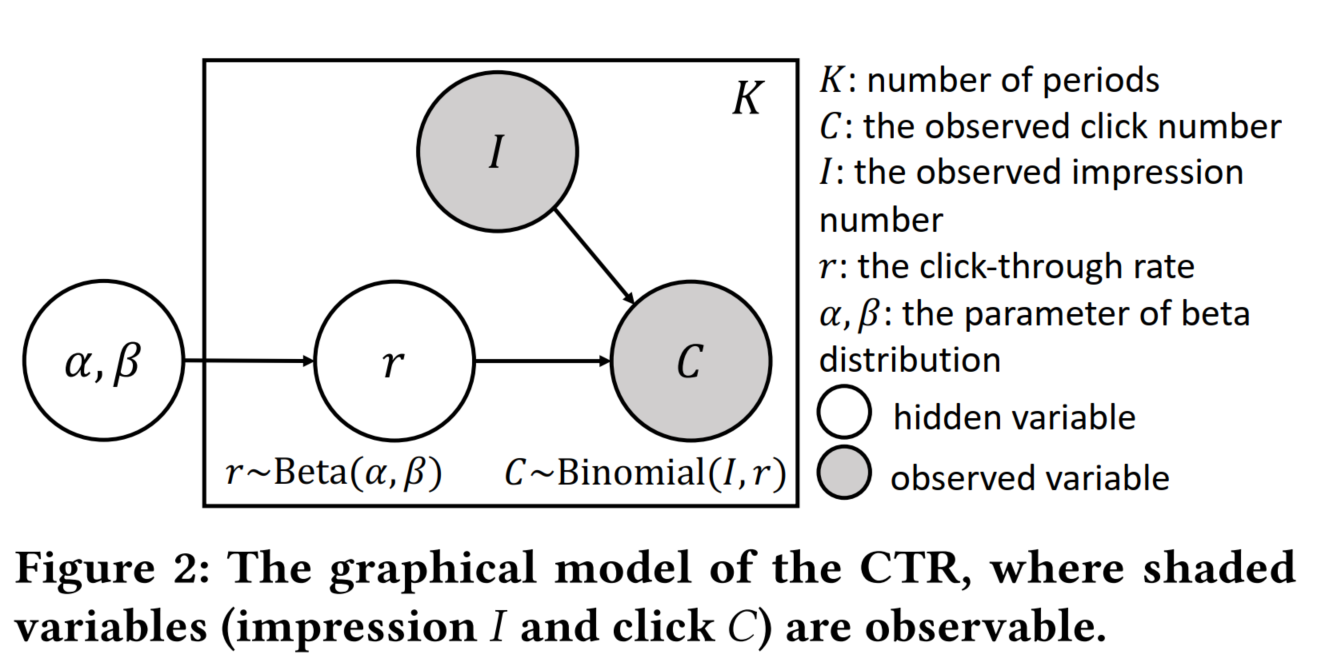
为了解决这一问题,研究团队提出了超越二元偏好 (Beyond Binary Preference, 简称 BBP) 训练框架。核心思路是将训练集的标签从二元取值范围增广为连续的取值范围,这样可以保证几乎所有的样本对之间都可以训练,以成倍地扩展可用的训练集规模。这种标签增广方案基于贝叶斯方法,根据研究团队对业务数据的洞察,将历史数据视为伯努利实验序列,并通过贝叶斯平滑为每一个训练集的用户和item学习各自的后验概率分数。这样,在优化排序损失时就可以综合考虑点击标签以及后验概率分数。
在大量的离线实验和在线 A/B Test 中验证了研究团队的方法,BBP 在排序和校准能力上均显著(p值<0.05)优于目前的所有 SOTA 方法。在两个腾讯互娱产品的在线部署上,BBP都相对提升了至少 10.28% 的新增好友数目。
论文3
论文题目:Truthful Bandit Mechanisms for Repeated Two-stage Ad Auctions
作者及单位:
李昊明(上海交通大学) ,刘宇牟(香港中文大学深圳),郑臻哲(上海交通大学), 张知临(阿里巴巴集团),徐俭(阿里巴巴集团),吴帆(上海交通大学)
在线广告平台通常采用多阶段拍卖框架,首先,在第一阶段从庞大的广告库中筛选出一小部分表现较好的候选广告子集。随后,在第二阶段,通过利用更精细化的模型预测点击率,并在这一候选子集中实施拍卖流程,从而确定最终展示的广告及其相应费用。设计一个有效的两阶段拍卖机制,既是非常重要也是具有挑战性的。在本研究中,我们关注于第一阶段的子集选择策略在线学习算法的研究,同时确保在重复的两阶段广告拍卖中维持博弈论性质。具体而言,我们提出了一种基于通用奖励函数的组合多臂老虎机机制设计问题,并确保了激励兼容与个体理性得到满足。我们发现,要设计一个同时具备次线性遗憾界且保证激励兼容的多臂老虎机机制面临重大挑战。为应对这一难题,我们引入近似的激励兼容神谕,并通过近似遗憾来评价机制的性能。我们设计了两种机制,第一个为“探索后利用”机制,其遗憾值达到了T^{2/3},而第二个机制则通过特定假设优化,实现了更低遗憾。理论证明,两种机制均保证激励兼容和个体理性,展现出良好的机制性能。
论文4
论文题目:Robust Auto-Bidding Strategies for Online Advertising
作者及单位:林祺龙(上海交通大学) ,郑臻哲(上海交通大学),吴帆(上海交通大学)
在在线广告中,现有的自动竞价策略主要采用先预测市场价格分布然后计算最优出价的方法。然而,需求方平台(DSPs)能获得的市场价格信息非常有限,相关的不确定性使得DSPs难以准确估计市场价格分布。为了解决这一挑战,我们对DSPs获取市场价格信息的过程进行了全面分析,并从中提取了两种类型的不确定性:已知不确定性和未知不确定性。基于这些不确定性,我们提出了两级鲁棒竞价策略:针对审查的鲁棒竞价策略(RBC)和针对分布偏移的鲁棒竞价策略(RBDS),它们在不确定条件下为最坏情况下的收益提供保证。公共数据集上的实验结果表明,我们的鲁棒竞价策略使得DSPs在测试集和最坏情况下都能实现更高的收益。
论文5
论文题目:Preventing Strategic Behaviors in Collaborative Inference for Vertical Federated Learning
作者及单位:邢译丹(上海交通大学),郑臻哲(上海交通大学),吴帆(上海交通大学)
纵向联邦学习 (VFL) 是一种针对多个参与方拥有相同样本空间、不同特征空间数据的新兴分布式机器学习范式。在 VFL 的推理过程中,各参与方需要上传其根据本地特征计算的嵌入向量以进行聚合,从而获得最终的预测结果。尽管 VFL 能够解决数据隐私保护下的跨机构模型训练问题,当前 VFL 系统的推理过程却很容易受到参与方策略行为的影响,因为参与方可以轻易更改推理过程中上传的本地嵌入向量,从而直接影响聚合后的预测结果。为了引导各参与方在推理过程中上传真实的本地嵌入向量,我们提出了一种基于分布信息的惩罚机制,以检测和惩罚协作推理中更改嵌入向量的策略行为。我们的机制利用统计理论中的双样本检验来区分上传嵌入向量的分布是否合理,并通过使不诚实参与方的上传无效化来进行惩罚。我们证明了该机制可以使真实上传本地嵌入向量的参与方策略收敛到贝叶斯纳什均衡。基于真实数据集的实验结果进一步表明了该机制可以有效减少参与方策略性操纵上传嵌入时的效益,从而促使各参与方在VFL推理过程中上传真实的本地嵌入向量计算结果。
论文6
论文题目:Online Preference Weight Estimation Algorithm with Vanishing Regret
for Car-Hailing in Road Network
作者及单位:
高宇岑(上海交通大学),朱哲昊(上海交通大学),马鸣谦(上海交通大学),郜飞(滴滴出行),高徽(滴滴出行),时阳光(山东大学),高晓沨*(上海交通大学)
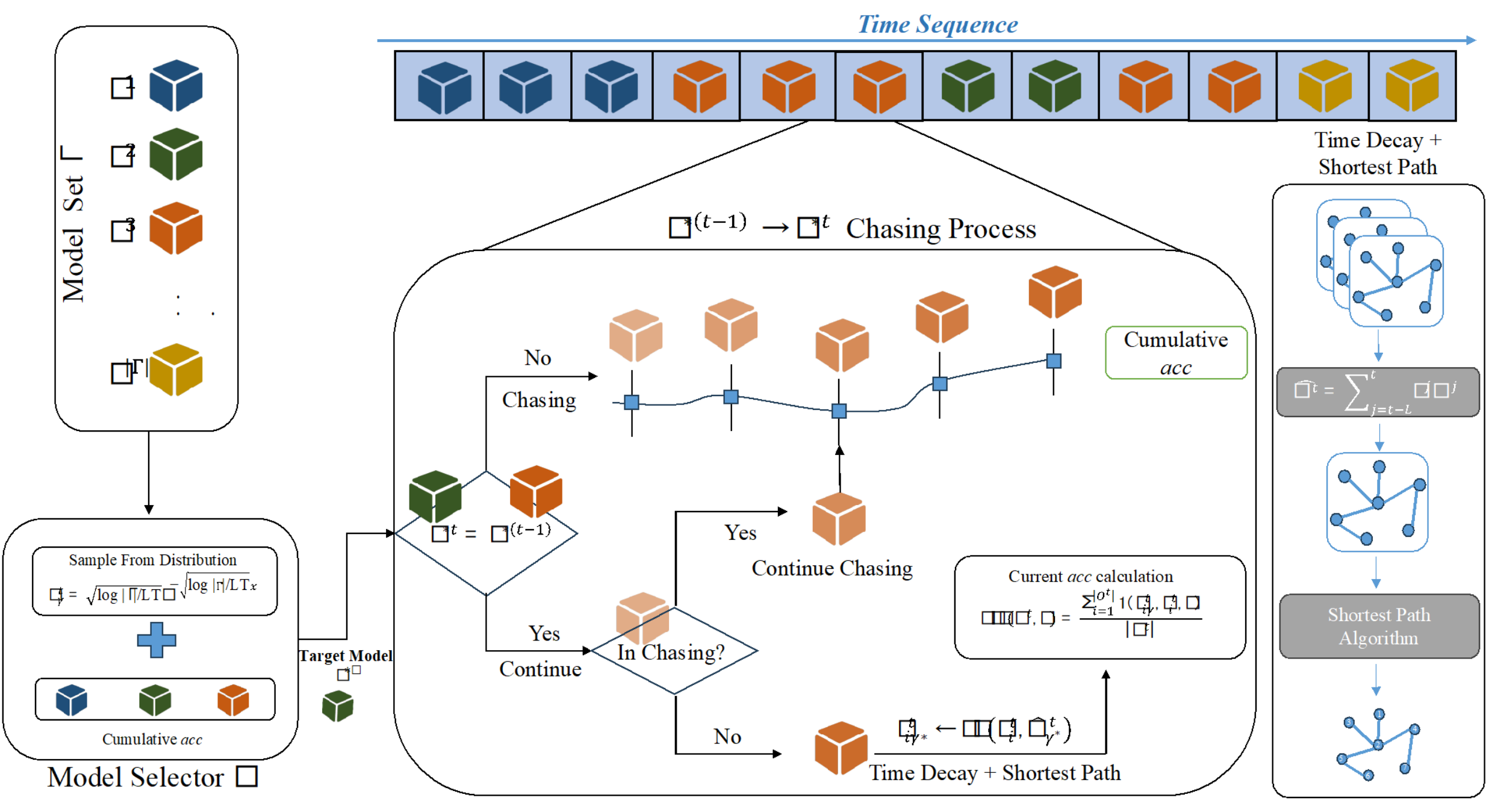
网约车服务在现代交通运输系统中扮演着重要的角色,路径规划问题是其中的关键问题之一。一种被广泛采用的路径规划方式是为道路分配权重,再使用最短路算法计算路径。本文考虑在线的偏好权重估计问题,其核心目标是在线的估计每条道路的偏好权重以使得最短路算法计算得到的路径尽可能符合大众偏好。因为用户偏好随时间动态变化,现有的方法不能实现理论性能保障。因此,本文提出了一种基于在线学习的偏好权重追踪算法Preference Weight Chasing(PWC),并证明其针对任意的情况相较于事先固定的最佳模型能够实现平均损失趋近于零。我们在多个真实的城市数据集上进行了实验,验证了所提出算法的有效性。
论文7
论文题目:Integrating System State into Spatio-Temporal Graph Neural
Network for Microservice Workload Prediction
作者及单位:
罗旸(上海交通大学),高墨涵(上海交通大学),余哲梦(上海交通大学),葛昊元(蚂蚁集团),高晓沨*(上海交通大学),蔡腾纬(蚂蚁集团),陈贵海(上海交通大学)
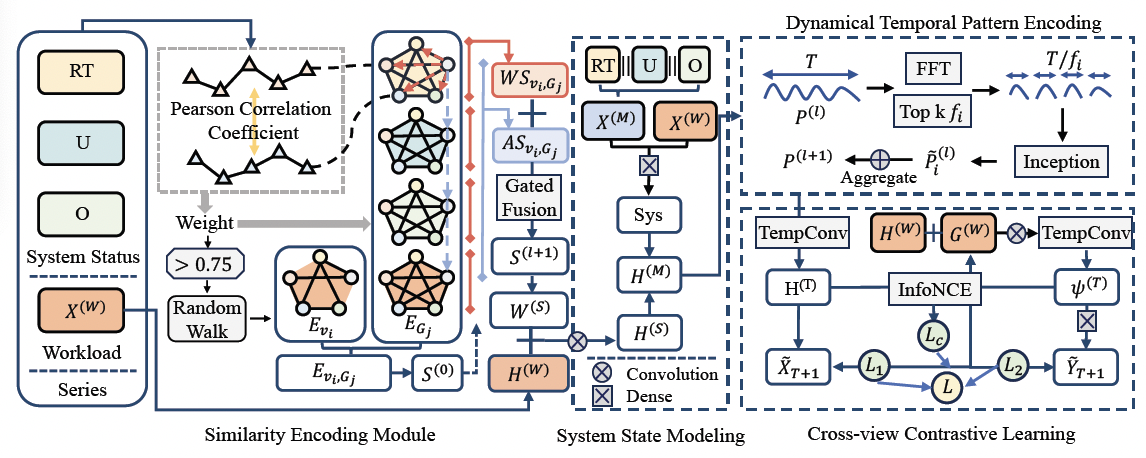
微服务架构在提升网络应用程序的模块化和可扩展性方面发挥着关键作用,在支付宝等大型应用上展现了广泛应用前景。但是,这类架构常遇到的问题是,由于资源配置不够灵活,导致CPU等关键计算资源使用效率低下。这加大了对动态且精确工作负载预测模型的需求,以便优化资源调度。面对这一需求,我们设计了STAMP,一种专为预测微服务工作负载的时空图神经网络模型。STAMP旨在全面考虑微服务间的复杂交互、工作负载随时间的变化,以及系统状态对资源利用的影响。STAMP利用图结构来描绘微服务间的交互模式,有效抽象了微服务网络的复杂联系。它结合时间序列分析来把握工作负载变化的趋势,并整合系统状态信息来提升预测的准确性。在三个真实微服务数据集上的测试显示,与现有基线模型相比,STAMP的预测精确度平均提高了5.72%。在支付宝云平台的实际线上测试中,STAMP的运用能够节省33.10%的CPU资源消耗,带来了经济效益的同时促进了绿色计算发展。
论文8
论文题目:DisCo: Towards Harmonious Disentanglement and Collaboration between Tabular and Semantic Space for Recommendation
作者及单位:杜蔻年华(上海交通大学),陈垍铮(上海交通大学),林江浩(上海交通大学),西云佳(上海交通大学),王航宇(上海交通大学),戴心仪(华为诺亚),陈渤(华为诺亚),唐睿明(华为诺亚),张伟楠(上海交通大学)
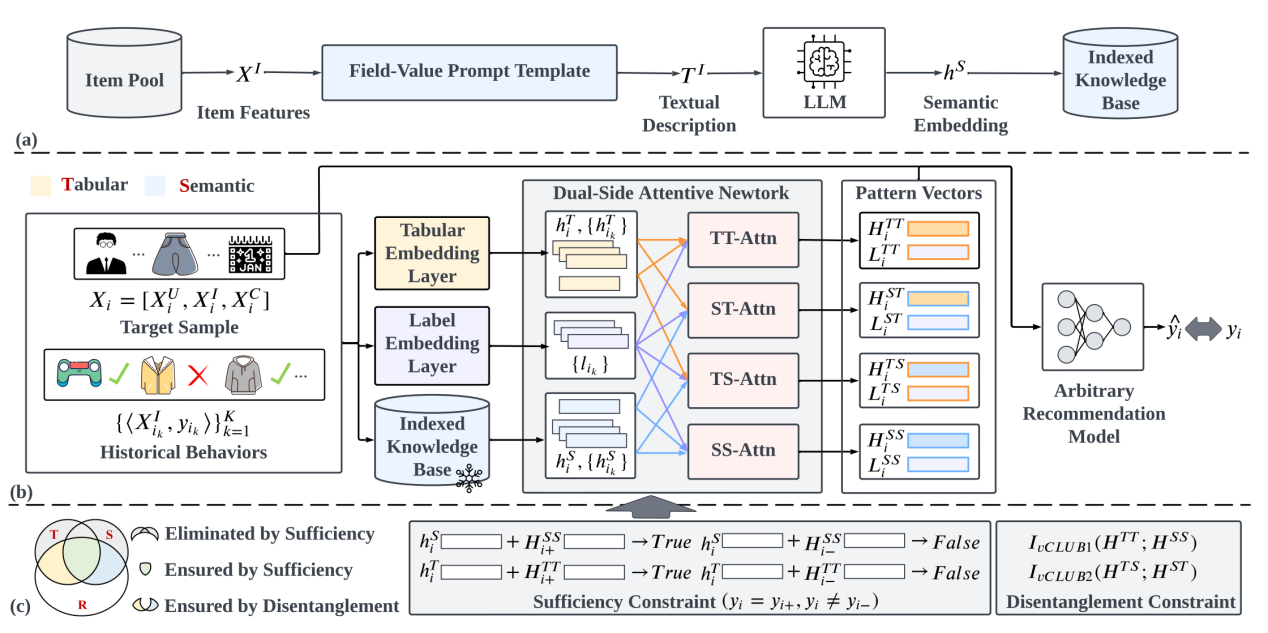
推荐系统在电子商务、社交媒体等各种应用中扮演着重要角色。传统的推荐方法通常在表格表示空间内建模协同信号,尽管这些方法在个性化建模和效率方面表现出色,但数据集中潜在的语义依赖被忽略了。随后出现了将语义引入推荐的方法,从语义表示空间注入知识,在推荐模型中注入了通用语言理解能力。然而,现有的语义增强推荐方法侧重于对齐两个空间,在此过程中,两个空间的表示往往会变得接近,使得两个空间中独特的模式被丢弃、未得到很好的探索。在本文中,我们提出了DisCo,以解缠两个表示空间中的独特模式并协作两个空间以增强推荐,捕捉两个空间的特异性和一致性。具体来说,我们提出了1)双侧注意力网络来捕捉领域内模式和领域间模式,2)充分性约束来保留每个表示空间的任务相关信息并过滤噪声,以及3)解缠约束来避免模型丢弃空间独特信息。这些模块在解缠和协作两个表示空间之间取得了平衡,产生了信息丰富的模式向量,可以作为额外特征附加到任意基座推荐模型上以增强性能。实验结果验证了我们的方法相对于不同模型的优越性以及DisCo在不同基座推荐模型上的兼容性。论文还进行了各种消融研究和效率分析,以证明每个模型组件的合理性。
论文9
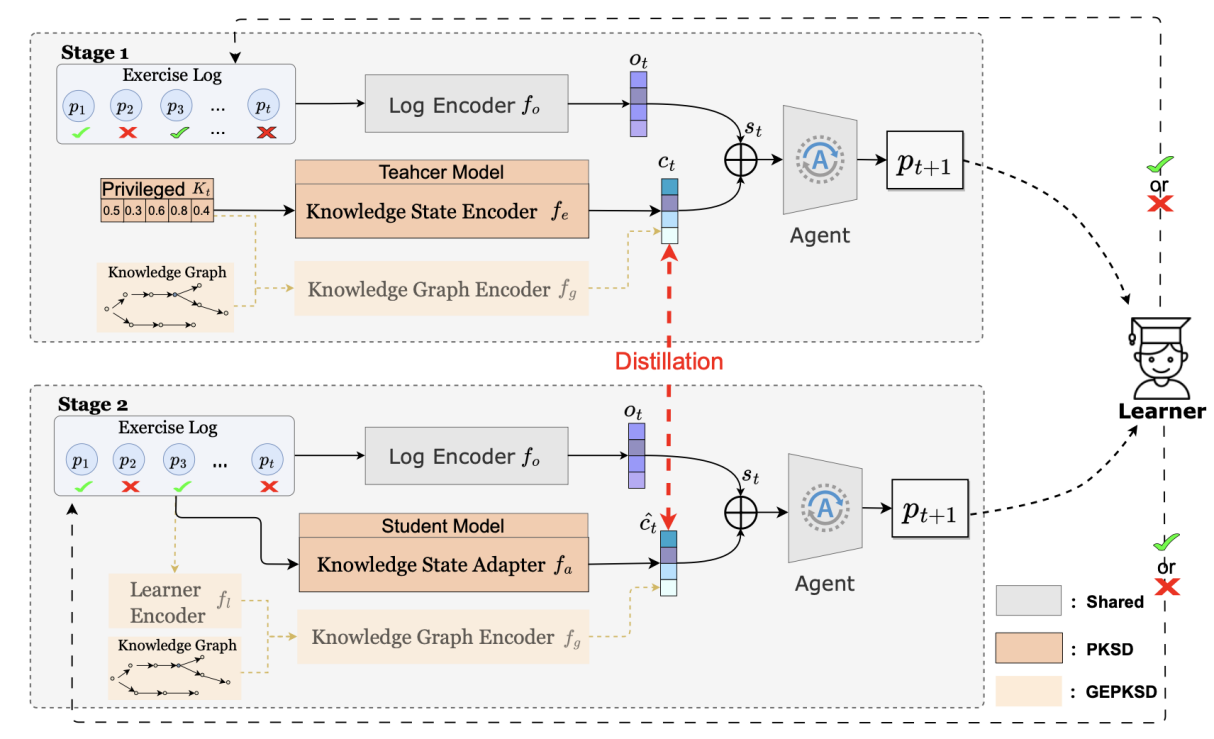
论文题目:Privileged Knowledge State Distillation for Reinforcement Learning-based Educational Path Recommendation
作者及单位:李庆尧(上海交通大学),夏伟(华为诺亚),殷力昂(上海交通大学),晋嘉睿(上海交通大学),俞勇*(上海交通大学)
教育路径推荐旨在根据学习者的能力推荐适合的知识概念,从而提供个性化的学习体验。近年来,强化学习(RL)方法通过将学习者的学习记录编码为状态,并使用基于RL的智能推荐算法进行合适的推荐,取得了显著的成果。然而,由于不同的学生构成了动态变化的环境,使得这些方法在面对学习者多样化的知识状态时存在困难。在本文中,我们引入了优势特征蒸馏技术,并提出了优势知识状态蒸馏(PKSD)框架,使RL推荐算法能够在状态编码中利用实际知识状态作为优势特征,从而避免了追踪学生知识状态的困难,并基于此定制推荐以满足个体需求。具体而言,PKSD在训练过程中将优势知识状态与学习记录的表征一起作为状态表示。通过蒸馏,我们将适应学习者的知识状态的能力转移到知识状态适配器上。在推理过程中,由于实际知识状态不可访问,知识状态适配器将估计优势知识状态的隐层表征,代替优势特征进行推荐。考虑到教育中知识概念之间的紧密联系,我们进一步提出将图结构学习与PKSD框架结合,这种新方法称为图增强优势知识状态蒸馏(GEPKSD)。由于我们的方法是模型无关的,我们在4个公开的学生模拟器上将PKSD和GEPKSD与5种不同的RL基础方法结合进行了评估。结果验证了PKSD可以在各种RL方法中持续提高教育路径推荐效果,而GEPKSD在所有模拟中可以进一步增强PKSD的效果。